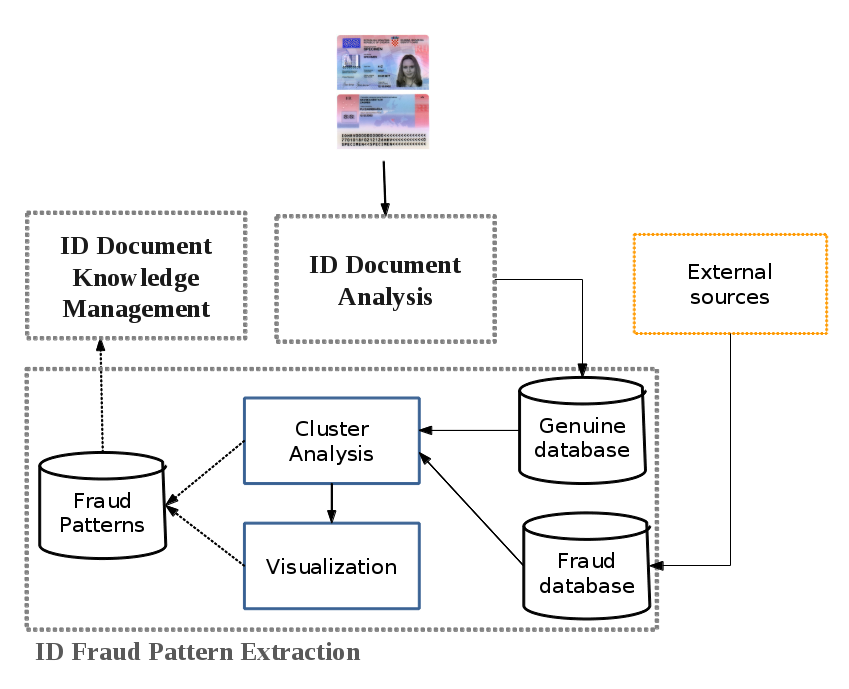
ID Fraud Pattern extraction
Many ID fraud activities are based on common professional sources that control this increasing black market. A simple individual analysis of ID documents does not help to uncover these sources. Therefore, the efforts in this part will be placed on analyzing the cumulative quantity of detected false documents in order to find out potential forensic links between them. Extracting such similarity groups will be of a great importance to detect the common sources, and to study new falsification techniques and trends. Cluster analysis methods will be used to discover relations between false IDs in their multidimensional feature space. This pattern extraction module will be coupled with a suitable visualization mechanism in order to facilitate the comprehension and the analysis of extracted groups of inter-linked fraud cases. It is worth mentioning that the knowledge management module will allow an easy and direct exploitation of any new suggested control rules within the automatic ID analysis and the verification module.
In this part, we will address the following issues:
- A data analysis solution to detect forensic links between false identity documents. Different points must be considered in this research: non-stationary environment, fuzzy ID relationships, missing information, temporal dimension, etc. Given that ID forensic features can be redundant and correlated, feature selection problem will also be addressed;
- An intuitive visualization tool in order to allow an easy analysis of detected fraud profiles (graph-based representation of multi-dimensional data, time drift visualization, etc.