ID Document analysis
The first objective of the IDFRAud project consists in proposing an automatic solution for ID document analysis and integrity verification.
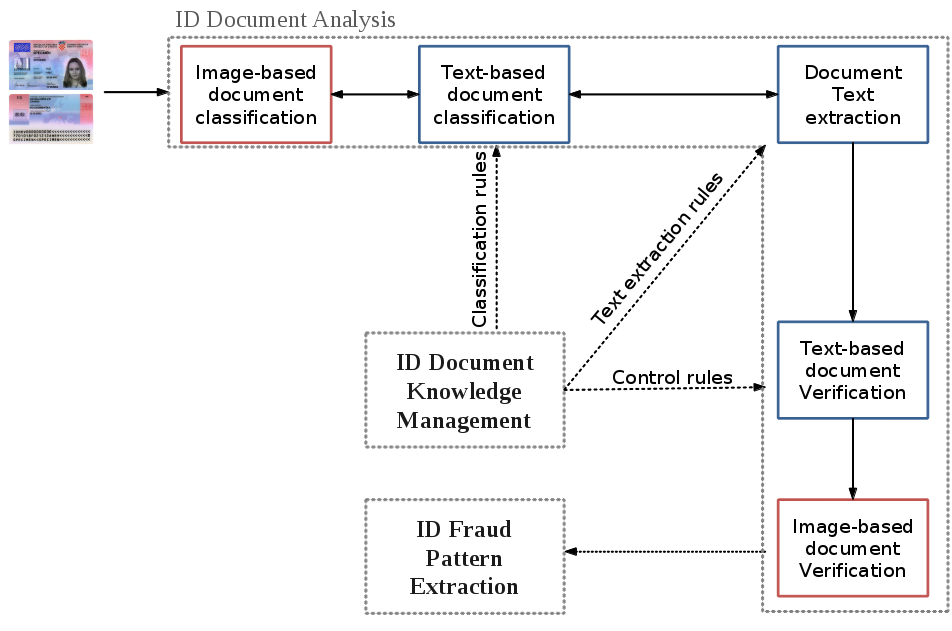
An ID document goes through three processes: classification, text extraction, and ID verification. The classification module aims at defining the ID family (type, country, and version). Both image-based and text-based approaches will be used to achieve a precise classification. The document goes then through several technical modules in order to extract its content (binarization, noise removal, zoning, OCR, etc.). The forensic authentication process is then executed over both visual (under white and ultraviolet light) and textual ID data. This ID verification process will rely on a set of rules that are externalized in a formal manner in order to allow easy management and evolving capabilities.
Two main scientific problems need to be addressed in this part:
- The first one is the design of a new approach of hierarchical fine-grained visual document classification. We will be looking for fast and evolving classification technique with an incremental learning algorithm;
- The second scientific challenge is to propose an extension of existing visual features – used for natural image categorization – to cope with the particularities of identity documents.