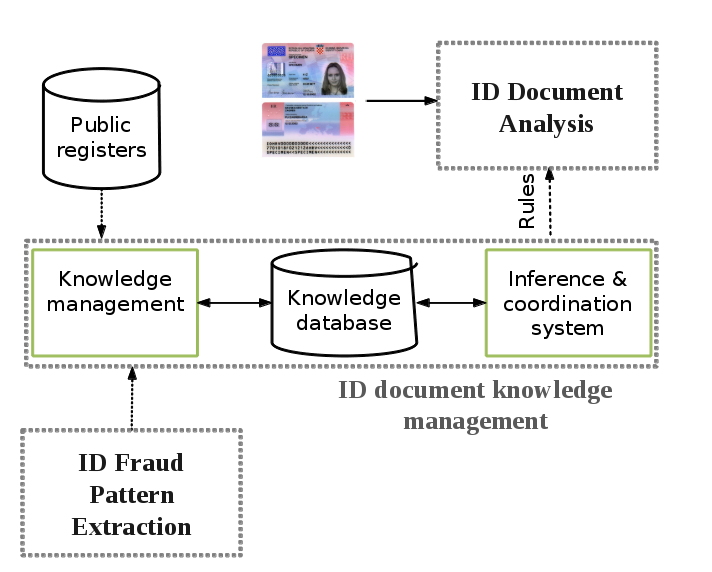
ID Document Knowledge Management
The objective is to organize ID models and ID analysis rules in a knowledge base (KB), so that global coherence between models and rules becomes easy to maintain when models and rules are inserted/modified/deleted. The knowledge base will integrate information from public registers (e.g., Prado), and from the output of ID fraud analysis.
The objective for this KB will be to cover the largest possible number of ID models with the greatest level of details deemed useful for ID analysis and verification. ID analysis rules will be based on the knowledge about ID models and will be used to decide at each step of the verification process which classifier/extractor/verifier to run in order to refine the classification/extraction/verification of the ID document under analysis.
Three main scientific problems need to be addressed in this part:
- The first one is to design a formal representation of ID models that can cope with their high heterogeneity and the different levels of trust that can be given to different features of ID models;
- The second problem is to support the frequent evolution of the knowledge base (e.g., new ID model, finer description of an ID model), helping KB maintainers to detect and correct inconsistencies in the description of models, as well as similarities between ID models that could result in classification errors;
- The third scientific problem is to tightly combine classification, extraction, and verification, and to automatically extract the ID analysis rules that coordinate those tasks from the KB. Such a combination is quite original as those tasks are generally worked out in isolation but is essential because of the complexity of ID analysis and verification. Indeed, a coarse classification may be necessary in order to extract an information (e.g., the MRZ), which in turn may be useful to refine the classification of the ID document, which in turn may be required to apply a verification process (e.g., checking the presence of a logo).